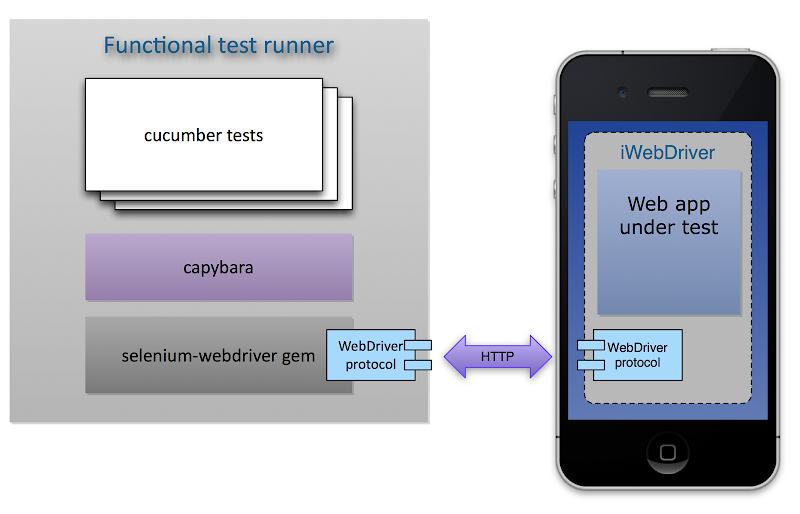
You’ve heard about how awesome Frank is and you’re all fired up about getting some automated functional testing set up for your iOS app. Now you’re ready to start writing your first test. In this article I’ll cover the fundamentals of writing Frank tests, using an open source iOS application written for the 2012 Olympic Games as an example.
get the code for your app
I’m guessing you’ll already have the code for your own app, but if you’d like to follow along with the examples in this post you’ll want to download the sample app I’m using. You’ll find it on github here. Create a local clone of that repo with git clone https://github.com/Frahaan/2012-Olympics-iOS--iPad-and-iPhone--source-code.git
Now open up the app in XCode and make sure you can run it in the simulator.
Frankify your app
Open up a terminal, and cd into the project’s root directory (the one with the app’s .xcodeproj file in it). Now we can Frankify the app as follows:
- install the frank-cucumber gem if you haven’t already by running
sudo gem install frank-cucumber. That sudo part won’t be necessary if you’re using rvm to manage your ruby setup (which I’d recommend). - run
frank setupto create a Frank subdirectory which contains everything necessary to Frankify your app. - run
frank buildto create a Frankified version of your app. - run
frank launchto launch the Frankified app in the simulator. - check that you are indeed running a Frankified version of the app by running
frank inspect. This will open up Symbiote in your web browser.
Symbiote
Symbiote is a little web app which is embedded into your Frankified app. It allows you to inspect the current state of your app as it’s running. It also lets you experiment with view selectors. View selectors are how you specify which views in your app you want to interact with or inspect the value of. If you’re familiar with CSS selectors or XPath expressions the concept is the same.
Let’s learn a bit more about selectors by experimenting with our example Olympics app. I’ve followed the steps above, and am looking at the home screen of the app in Symbiote.
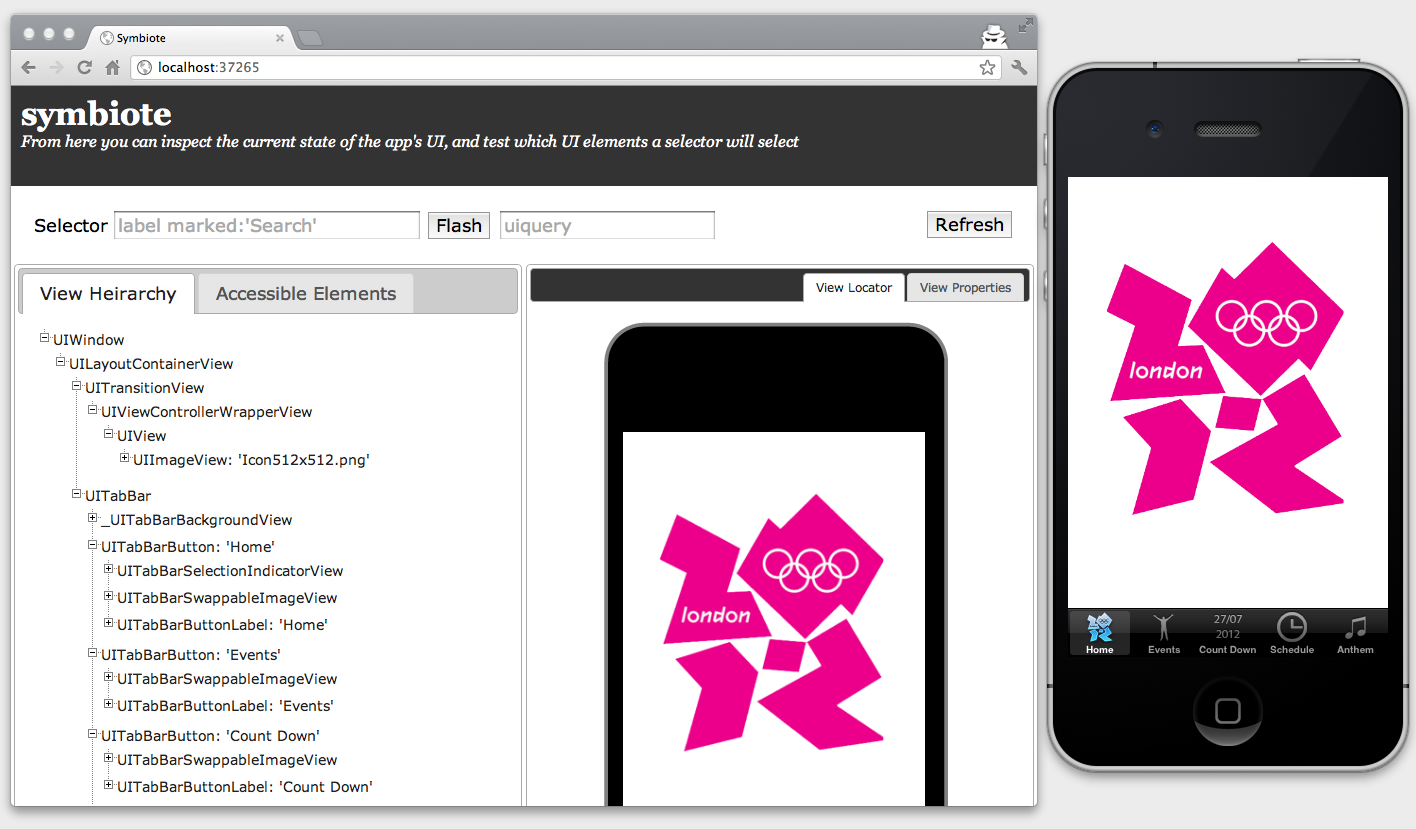
Note that I have the actual iOS Simulator side-by-side with my web browser. That’s useful when testing view selectors in Symbiote, because the main way of testing selectors is to flash the views in the simulator which match a selector. Let’s try that now. Type view marked:'Events' into the selector field at the top left of Symbiote in the web browser, and then hit the Flash button. You should see the Events button in the simulator flash. Congratulations, you are using Frank to manipulate specific parts of your iOS app.
running our first cucumber test
Our goal is to use Frank and cucumber to run automated tests against our app. The frank setup command provides an initial cucumber test for you so that you can verify that cucumber is working correctly in your system. First off we need to tell cucumber where our Frankified app is located so that cucumber can launch the app at the start of each test scenario. To do this, open up Frank/features/support/env.rb. At the bottom of that file you’ll see a TODO comment about setting the APP_BUNDLE_PATH. Replace that section of the file with something like this:
1
| |
This tells Frank the location of your Frankified app, relative to that env.rb file. Now that we have done that we can run the initial cucumber test that was provided as part of frank setup. To do that simple run cucumber in a terminal from the Frank subdirectory. When you do that you should see the Frankified app launch in the simulator, and then perform some rotations. You’ll also see some output in the terminal from cucumber describing the test steps it has performed and eventually declaring the test scenario passed.
writing our own cucumber test
All right, now that we know how to run cucumber tests we should write our own. We’re going to write a cuke test which verifies that the tab navigation buttons in our example Olympics app work correctly. We’ll write these tests in a new feature file called Frank/features/navigation.feature. Create that file with the following content:
1 2 3 4 5 6 7 8 | |
This expresses a test scenario. Now let’s ask cucumber to test just this feature by running cucumber features/navigation.feature. You should see the app launch, but then cucumber will complain because it doesn’t know how to execute any of the steps we’ve described after launching the app. That’s fair enough; we haven’t defined them anywhere yet! Let’s do that now.
Create a step definition file called features/step_definitions/navigation_steps.rb. When cucumber encountered the undefined steps just now it outputted a bunch of boilerplate code for defining those steps. We’ll cut and paste that code into our new step definition file. You should end up with this:
1 2 3 4 5 6 7 8 9 10 11 | |
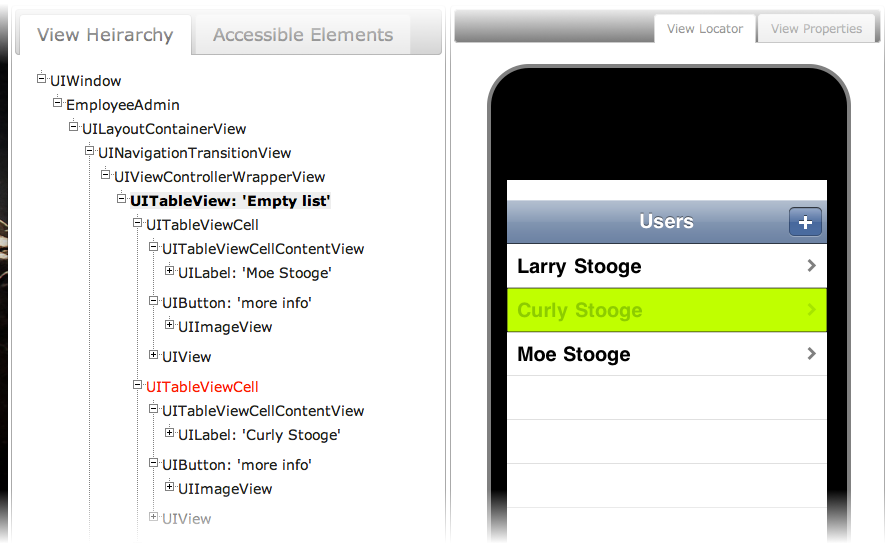
Now we’re going to implement these step definitions one at a time. Let’s start with the first one. We need to check that we are on the home screen. Looking at the home screen in Symbiote it consists of a big UIView with a UIImageView inside of it called Icon512x512.png. Our test can verify that the app is displaying the home screen by checking whether that UIImageView is in the view heirarchy. If it is then presumably we’re on the home screen. If we don’t see that view then we’re not on the home screen. This isn’t an ideal way of verifying where we are - for a start that image view should have a better accessibility label which would make our tests less brittle and coincidentally also make the VoiceOver experience better - but it will do for now.
To test whether a view exists we create a view selector which selects a UIImageView with the correct accessibility label and then we ask frank to verify that that selector matches at least one view. The entire step definition will look like this:
1 2 3 | |
Now when we run the cucumber feature again with cucumber features/navigation.feature we should see that step show up as green and passing in cucumber’s output. We are indeed at the Home screen at launch, and our test has verified that. One step down, two to go!
Next we need to define the step which navigates to a specific tab. To do that we’ll ask frank to touch the appropriate tab button in the UI. Looking in Symbiote it appears that those buttons are implemented as views of class UITabBarButton. We can also see that UIKit is giving them nice acccessibility labels. This means all we need to do to implement this step is something like this:
1 2 3 | |
If I run the feature again with cucumber I should see that step executing and taking us to the Events screen in the UI.
Now we’ll write our final step definition. We need to check that we are on the Events screen. Back in Symbiote if we inspect the view heirarchy for that screen we see a UIScrollView which contains a bunch of different buttons for the different Olympic events. I suppose a reasonable check for whether we’re on this screen would be to look for a few of those buttons. Again, this isn’t ideal but it should work pretty well. Here’s our step definition for that:
1 2 3 4 5 | |
And with that we are done. Running our feature again should result in a green, passing cucumber test. Hurray, we have written our first Frank test!
Don’t forget to refactor
Hang on, before we rush out to celebrate let’s clean up a bit. That last step has loads of duplication in it. Let’s refactor it a bit to this:
1 2 3 4 5 | |
That seems a bit cleaner to me. We run our tests again to make sure we’re still green.
Now we can go out and celebrate our first Frank test!
Where to turn for help
Frank is a pretty powerful tool, and it does take time to learn the nooks and crannies of Frank. This is particularly true if you are also new to ruby and/or cucumber.
testingwithfrank.com has documentation, screencasts, and links to more resources.
The frank mailing list is a particularly great resource. Lots of folks there have gone through the same learning process you will go through, and are happy to help.